Pandas 는 데이터 처리를 위해 필수적으로 알아야 할 모듈입니다.
저 같은 경우엔 자동화도구를 만드는 데 사용하고 있습니다! 딥러닝에선 데이터를 사용하기 위하여 전처리를 하기에도 굉장히 적합합니다.(회사 교육에서 잠깐 맛을 본 적이 있습니다 ㅎㅎ)
이번 글은 아주 기초적으로 설명드리도록 하겠습니다! 쭉 따라오시면 pandas사용하시는데 힘들었던 것이 해결될 거에요.
믿고 따라와 보세요!
- Pandas란?
pandas는 모듈이고 우린 이 모듈을 사용한다. 이 모듈은 어떤 개발자(Wes McKinney)가 자동화도구를 편하게 하기 위해 pandas라는 모듈을 만들고 거기 내부에 DataFrame 란 class 를 만들어 우린 그 class 를 사용하여(객체를 생성하여) 데이터처리를 합니다.
- 아래 코드는 우선 pandas모듈을 사용하기 전에 import하는 것입니다.
그런데 사용하기 위해서 우선 모듈을 설치해야겠죠? pip install pandas나 conda install pandas를 통해 설치하면 됩니다.
라인1 : pandas모듈을 import하고 pd약자로 사용하겠다.
라인2 : pandas모듈을 import한다. 사용을 위해선 pandas를 사용한다.
라인4 : 라인2에서 import한 pandas내 DataFrame 객체를 생성하고 df_test 인스턴스를 만든다.
라인5 : 라인1에서 import하고 pd약자로 사용하기로 하여 pd. 으로 사용한 것이고 DataFrame 객체를 생성하고 df_employee 인스턴스를 만든다.
라인2, 4 는 모듈 사용 시에 이와 같이 사용할 수 있다는 예시입니다. pandas를 사용할 때 약속처럼 pd를 사용합니다^^
|
1
2
3
4
5
|
import pandas as pd
import pandas
df_test = pandas.DataFrame()
df_employee = pd.DataFrame()
|
cs |
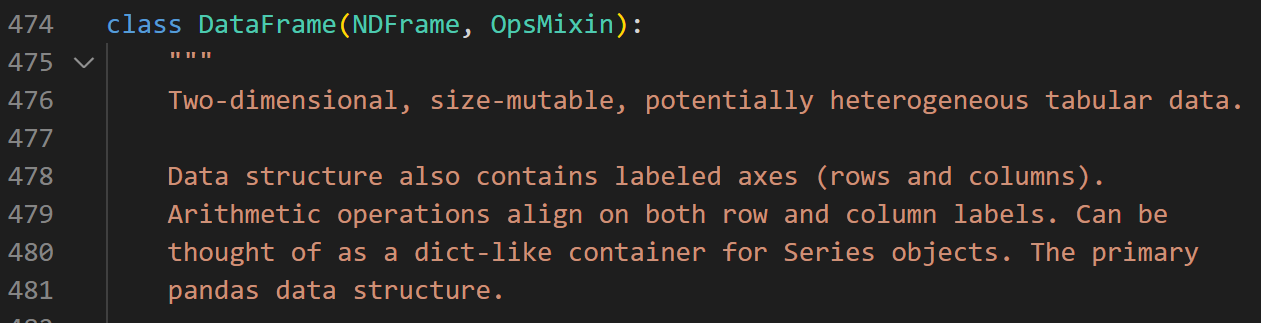
- 직원 정보를 저장하는 아래와 같은 "그림1. 목표 dataframe" 을 만들어볼까요? (데이터 프레임 만들고 데이터 추가)

우선 DataFrame(데이터프레임)이 뭘까요?
데이터 프레임이란 pandas에서 row와 column 즉 행과 열로 되어있는 구조를 데이터 프레임이라고 부릅니다. 엑셀을 생각하시면 데이터가 저장되는 그 형태를 마치 데이터프레임이라고 보면 됩니다. 위의 그림1에서 row는 좌측에 0, 1, 2 를 말하고요 index라고 부릅니다. column은 Name, Phone, Email, First day of work 를 말합니다.
아래 코드를 설명하면서 이해시켜 드리겠습니다.
라인 1 : pandas모듈을 import하고 pd약자로 사용하겠다.
라인 3: pd.DataFrame() pandas모듈을 pd로 줄여서 사용하였고 해당 DataFrame(class) 객체를 사용하고 df_employee라는 인스턴스를 생성하겠다!라는 것입니다. 아래 그림1에 DataFrame class코드를 그냥 스크린샷 해왔습니다. 이 class 를 사용하겠다라는 것이죠~
라인 5~8 : column 을 만들고 해당 column에 데이터를 넣는 코드로 예를 들어 df_employee["Name"] 이라는 column을 만들고 거기에 데이터를 list로 넣었다라고 보면 됩니다.
라인10 : 실행하면 그림2과 같이 나옵니다! 그림2는 DataFrame class가 정의되어 있는 것을 스크린샷 한 것입니다. (주피터 노트북이라 df_employee를 바로 적어서 실행되지만 만약 스크립트(.py)파일로 실행하고자 한다면 print(df_employee) 를 적어주셔야 console에서 확인하실 수 있습니다.
|
1
2
3
4
5
6
7
8
9
10
|
import pandas as pd
df_employee = pd.DataFrame()
df_employee["Name"] = ["하나", "다음", "둘"]
df_employee["Phone"] = ["010-1111-1111","010-0000-0000", "010-2222-2222"]
df_employee["Email"] = ["one@naver.com","next@gmail.com", "two@naver.com"]
df_employee["First day of work"] = ["2001-01-01","2002-02-02","2003-03-03"]
df_employee
|
cs |
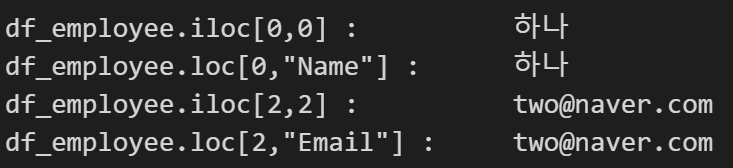
- 데이터 프레임(data frame)에 데이터 값 확인하기(iloc, loc)
iloc, loc 을 사용하여 데이터를 불러올 수 있습니다.
iloc : iloc[row index, column위치] - integer location 의 약자로 정수로 데이터값의 위치를 확인합니다. row index는 반드시 넣어줘야 하지만 column위치는 데이터를 넣지 않으면 모든 column데이터를 가져옵니다.
loc : loc[row index, column 이름] -location 의 약자로 데이터값의 위치를 확인하는데 row index와 column 이름으로 위치를 확인합니다. row index는 반드시 넣어줘야 하지만 column이름은 데이터를 넣지 않으면 모든 column데이터를 가져옵니다.
아래 코드와 출력 결과를 보면 쉽게 알 수 있습니다.
라인1 : iloc을 사용하였고, df_employee.iloc[0,0] 의 데이터는? '하나' 입니다. index 0에 column은 0 인데 column도 0 부터 시작합니다. 그러니 Name = 0, Phone = 1, Email = 2, First day of work = 3 이 되겠죠?
라인2 : loc을 사용하였고, df_employee.loc[0,"Name"]의 데이터는? '하나'
라인3,4 : 위치만 변경하여 iloc, loc의 이메일 값을 가져왔습니다.
|
1
2
3
4
|
print("df_employee.iloc[0,0] : \t", df_employee.iloc[0,0])
print('df_employee.loc[0,"Name"] : \t',df_employee.loc[0,"Name"])
print("df_employee.iloc[2,2] : \t", df_employee.iloc[2,2])
print('df_employee.loc[2,"Email"] : \t',df_employee.loc[2,"Email"])
|
cs |
그런데 이렇게 단순히 작업하는 게 아닙니다. 이제부터 loc, iloc의 활용 시작입니다!
- iloc, loc 의 활용법 - 데이터 원하는 대로 가지고 놀기!
내가 원하는 데이터를 가지고 오고 싶으신 분들 잘 오셨습니다. 하나씩 설명드리겠습니다.
index에 들어오는 것은 말 그대로 index숫자를 적으면 원하는 데이터를 가져올 수 있습니다. 근데 아래와 같이도 가져올 수 있어요. 0, 1, 0 .~~~, 2 이런 식으로 가져오니 여러 개를 가져올 수 있습니다~! ㅎㅎ loc도 똑같습니다
|
1
|
df_employee.iloc[[0,1,0,2,1,0,1,2]]
|
cs |

index에 들어가는 형식 중 또 한 가지가 있는데 index의 수만큼 boolean 값으로 데이터를 가지고 오고 싶으면 True, 가지고오고 싶지 않으면 False ! 로 데이터를 추출할 수 있습니다.. 아래와 같이 index개수에 맞춰서 True, False 이런 식으로 넣어주면 True 데이터만 가져오게 됩니다.
|
1
|
df_employee.iloc[[True,False,True]]
|
cs |
|
1
|
df_employee.loc[[True,False,True]]
|
cs |

이를 이용해서 이제 조건에 맞는 데이터를 원하는 대로 가져와보겠습니다.
우선 위의 데이터에서 naver메일만 사용하는 사람을 가져와볼까요? 여기선 몇 가지 스킬이 필요한데요 하나씩 생각해 보면 Email에서 데이터를 가져와야 하니 어떤 데이터가 있는지 축약해 볼까요?
|
1
|
df_employee["Email"]
|
cs |

오호.. naver mail이 두 개 있군요 그러면! 이 데이터 중에서 naver가 포함된 문자열만 걸러주면 되겠네요?
그러면 아래와 같이 하면 됩니다. 설명하면 df_employee["Email"] 에서 .str 문자열 중에 . contains 포함된 문자열 중 "naver"가 있는지 확인해 달라.
|
1
|
df_employee["Email"].str.contains("naver")
|
cs |

그랬더니 출력이 어라 True, False, True !? 데이터 타입이 bool이네요?
다시 한번 데이터 타입을 확인해 볼까요? (pandas에서 데이터 타입을 확인하기 위해선 단수면 dtype, 복수면 dtypes를 붙여서 타입을 확인할 수 있습니다.)
|
1
|
df_employee["Email"].str.contains("naver").dtype
|
cs |

역시나.. 아니 당연히 위에서 표현한 대로 bool 타입이네요. 잠깐! 위에서 bool type으로 데이터를 가져올 수 있다고 했죠? 자... 끝났습니다. loc[index]에 위에서 나온 bool 타입을 넣으면?
|
1
|
df_employee.loc[df_employee["Email"].str.contains("naver")]
|
cs |

와!! 내가 원하는 데이터인 naver 메일을 사용하는 담당자 둘을 가져올 수 있게 되었네요! 근데 여기서 착각하시면 안 됩니다. df_employee 에 저장된 데이터는 전혀 변하지 않습니다. 아래 확인해 보면 loc을 검색했지만 그대로입니다. 기존 데이터는 그대로입니다.

만약 기존 데이터를 변경하고 싶다면 기존 데이터프레임에 넣어주면!?

df_employee의 데이터가 변경되었네요!! 어 그런데? 이상한 점이 하나 있습니다.. 발견하신 분 계신가요? 바로... index가 0, 1이 아니고 0, 2라는 점입니다. index 1을 실행해 볼까요?

에러가 나오게 됩니다..! 그러면 해결방법은? reset_index(drop=True)를 사용하면 됩니다!

오 그렇군요 index가 0, 1로 변경되었네요!! 그런데!! 다시 df_employee를 실행해 보면

어라.. index가 다시 0, 2로 되어있네요. 왜냐면 지금 작업한 것이 기존 데이터를 변경해주지 않거든요. 그래서 기존 데이터를 변경하고 싶으면 2가지 방법이 있는데 옆에 inplace를 True로 하면 내부적으로 df_employee 객체 내부의 데이터 값을 변경해 버리고요 다른 방법은 df_employee = df_employee.reset_index(drop=True) 처럼 그냥 데이터를 다시 넣어버리면 됩니다. 근데 inplace를 사용하는 것이 훨씬 깔끔하겠죠!

자 이번엔 column을 추가해 보겠습니다. 입사일을 가지고 입사 연도(First day of work)를 추가해 봅시다. 그러려면 column을 추가해야 할 것인데 입사 연도(Year of joining the company)에서 연도만 가지고 오기 위해서 문자열에 slicing을 하여 연도만 가져오려고 합니다. 그런데 어떻게 slicing을 할 수 있을까요? 우선 위에서 봤던 str[:] 로 모든 문자를 출력하면 아래와 같이 나오게 됩니다. 딱 봐도 slicing할 수 있게 생겼죠~?

연도는 앞의 문자 4개만 가져오면 되니 아래와 같이 slicing 하면서 column을 "Year of joining the company" 에 추가하였고 dataframe인 df_employee를 출력하면? 데이터가 잘 들어가 있는 것이 보입니다.

그럼 이번에 입사 연차가 얼마나 되었는지 만들어 보겠습니다.
아래와 같이 올해 2023년에서 바로 위에서 만든 "Year of joining the company" 의 값을 빼고 1을 더하면 입사 연차를 알 수 있겠죠? 자.. 실행을 해봅시다. 그런데 에러가 나오네요?


아.. type error 가 떴습니다. this_year는 int 이고 위에선 "Year of joining the company" column은 문자열을 자른 것이니 타입이 string이겠죠? 모르겠다고요? 한번 확인 보겠습니다 ㅎㅎ
맞군요 this_year 은 int, "Year of joining the company" 의 첫 번째 index의 값의 타입을 보았고 int, str이네요.

근데 왜 데이터 타입 옆에 class가 붙을까요? 라고 생각하는 분들이 있으실 텐데 간단하게 설명드리면 일단 파이썬은 모든 것이 class로 이루어져 있다고 해도 과언이 아닐 정도로 모든 것이 객체로 되어있습니다. 그렇기 때문에 문자를 "hello" + " world" 라고 해도 알아서 더해주는 것 같은 것을 아무 생각 없이 해보신 분들도 많을 텐데 만약 c++에서 이와 같은 것을 하려면 직접 class에 연산자 operator 를 사용하여 문자를 더할 수 있도록 하는 것이 있습니다. user가 만든 객체 내에서 각종 operator( +, - ,* , /, 등등..)을 사용할 수 있도록 하는 것을 연산자 operator라고 합니다. 저는 처음 c++에서 연산자 operator의 지식의 벽을 깨느라 머리가 깨질 뻔했던 적이 있었습니다.이와 같은 이유로 타입도 class가 붙게 되는 것이고 자동화도구를 만들기 정말 쉬운 언어라고 생각합니다.^^
자 다른 이야기로 빠져버렸는데 다시 설명드리면 "Year of joining the company" column 내 데이터를 int로 변경하 면하고 다시 위에서 입사 연도를 작업해 보면 되지 않을까요? 네 맞습니다. 아래와 같이 pd.to_numeric을 이용하여 객체 내부의 데이터를 모두 int로 변경할 수 있습니다.

위의 코드를 실행하고 내 dataframe 의 데이터 타입을 확인해 보면 Year of joining the company 는 int64로 변경된 것을 볼 수 있습니다.

자 그러면 다시 해볼까요??
와..!! yearof service(입사 연차)의 column이 이제 잘 추가된 것을 확인할 수 있네요!!

간단한 데이터 처리 사용법에 대하여 알아보았습니다.
사실 이 이외에도 엄청나게 많은 활용법이 있습니다. 이는 실제로 사용하면서 구글링, 네이버 검색 또는 직접 하나씩 만들어서 사용하여 코딩을 하나씩 할 수 밖에는 없습니다. 다만 데이터가 어떻게 들어가는지에 대한 이해가 없으면 처음에 접근하기가 힘든 분들에 대하여 글을 적었습니다.
모두 즐코딩 하세요!!
'Python > 기본개념' 카테고리의 다른 글
| python main함수 만들기(if __name=="__main__": ) (0) | 2023.03.31 |
|---|

댓글